需要在linux C/C++程序中生成一个文件,文件中包含中文字符,可是上库到代码中编译运行,发现生成的文件乱码,相同的代码,自己编写的demo生成的文件显示却正常。
为什么会出现相同代码,运行结果不同的问题呢?
原因是由于项目文件中使用的是ISO 8859-1编码,而我自己编写的demo使用的是utf-8编码,而ISO 8859-1编码无法识别中文字符,因此导致写入到文件乱码。
我们使用如下代码验证:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <limits.h>
#define MSG_LEN 4096
int save_config_info(const char *path, char* message)
{
FILE *fp = NULL;
fp = fopen(path, "wb");
if (!fp)
{
//打印日志
return -1;
}
if (fwrite(message, 1, strlen(message), fp) != strlen(message))
{
//打印日志
fclose(fp);
return -1;
}
fclose(fp);
return 0;
}
int main()
{
char str[MSG_LEN] = "配置文件中包含中文";
//char str[] = u8"\u914D\u7F6E\u6587\u4EF6\u4E2D\u5305\u542B\u4E2D\u6587";
char path[PATH_MAX] = "example.txt";
save_config_info(path,str);
return 0;
}
注意此时我们将代码编码格式设置为ISO 8859-1,通过vscode可以方便更改源文件编码,见下图右下角位置:
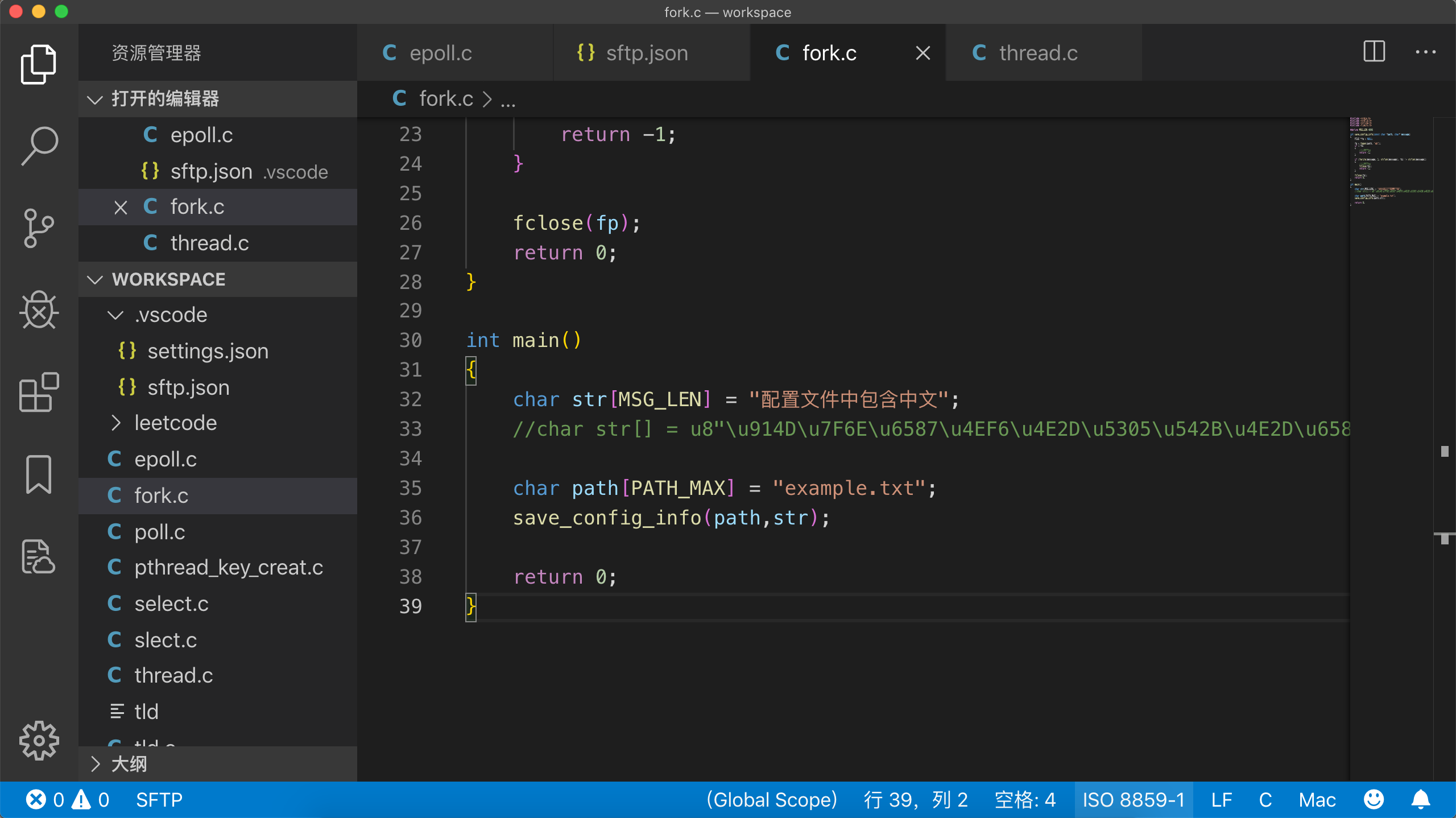
执行结果:
[root workspace]#gcc -g -o fork fork.c
[root workspace]#file fork.c
fork.c: C source, ASCII text
[root workspace]#./fork
[root workspace]#
[root workspace]#cat example.txt
[root workspace]#
[root workspace]#file example.txt
example.txt: ASCII text, with no line terminators
[root workspace]#如果将源文件更改为utf-8编码,然后重新编译运行,执行结果:
[root workspace]#file fork.c
fork.c: C source, UTF-8 Unicode text
[root workspace]#
[root workspace]#gcc -g -o fork fork.c
[root workspace]#
[root workspace]#./fork
[root workspace]#
[root workspace]#file example.txt
example.txt: UTF-8 Unicode text, with no line terminators
[root workspace]#
[root workspace]#cat example.txt
配置文件中包含中文[root workspace]#
[root workspace]#
分析到这里我们可以清晰的想到,解决方法有两个:
一:更改生成二进制的源代码编码格式为utf-8
二:将中文转成对应的十六进制表示
char str[] = u8"\u914D\u7F6E\u6587\u4EF6\u4E2D\u5305\u542B\u4E2D\u6587";
转换地址utf-8编码表
方法一存在缺陷,比如多人协作存在冲突,依赖源文件编码格式。
将str使用上述表示方法后,更改源文件编码格式为ISO 8859-1 或utf8,文件中存储的汉字均正常显示。
分享一篇对于Linux平台C语言乱码总结较好的文章: Linux平台C语言乱码