面试总结专题
用户态到内核态转换
操作系统的进程空间可分为用户空间和内核空间,它们需要不同的执行权限。其中系统调用运行在内核空间。
从用户态切换到内核态主要有如下几种方式:
1.系统调用
在电脑中,系统调用(英语:system call),指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态运行。如设备IO操作或者进程间通信。
2.异常
页缺失(英语:Page fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。
通常情况下,用于处理此中断的程序是操作系统的一部分。如果操作系统判断此次访问是有效的,那么操作系统会尝试将相关的分页从硬盘上的虚拟内存文件中调入内存。而如果访问是不被允许的,那么操作系统通常会结束相关的进程。
虽然其名为“页缺失”错误,但实际上这并不一定是一种错误。而且这一机制对于利用虚拟内存来增加程序可用内存空间的操作系统(比如Microsoft Windows和各种类Unix系统)中都是常见且有必要的。
3.中断
中断是用以提高计算机工作效率、增强计算机功能的一项重要技术。最初引入硬件中断,只是出于性能上的考量。如果计算机系统没有中断,则处理器与外部设备通信时,它必须在向该设备发出指令后进行忙等待(Busy waiting),反复轮询该设备是否完成了动作并返回结果。这就造成了大量处理器周期被浪费。引入中断以后,当处理器发出设备请求后就可以立即返回以处理其他任务,而当设备完成动作后,发送中断信号给处理器,后者就可以再回过头获取处理结果。这样,在设备进行处理的周期内,处理器可以执行其他一些有意义的工作,而只付出一些很小的切换所引发的时间代价。后来被用于CPU外部与内部紧急事件的处理、机器故障的处理、时间控制等多个方面,并产生通过软件方式进入中断处理(软中断)的概念。
进程间通信
每个进程各自有不同的用户地址空间,当进程间需要同步数据时,需要先将数据从用户空间拷贝到内核缓冲区,另一个进程再从内核缓冲区把数据拷走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)。
管道/匿名管道(pipe)
命名管道(FIFO)
信号(Signal)
消息队列
共享内存
信号量
套接字
go协程模型
简单来说协程是一种用户态、编程语言层面的轻量级线程。线程是靠操作系统OS本身来调度,是抢占式的任务处理方式,线程切换成本较高,因此需要控制线程数。
协程拥有用户态的上下文和栈,协程切换相对于线程切换非常轻量。协程本质是单线程,适合计算密集型。
协程也叫用户态线程,协程之间的切换发生在用户态。在用户态没有时钟中断,系统调用等机制,那么协程切换由什么触发?调度器将控制权交给某个协程后,控制权什么时候回到调度器,从而调度另外一个协程运行? 实际上,这需要协程主动放弃CPU,控制权回到调度器,从而调度另外一个协程运行。所谓协作式线程(cooperative),需要协程之间互相协作,不需要使用CPU时将CPU主动让出。
linux性能优化
性能分析工具
系统级工具有top sar vmstat netstat pstack strace perf
常用的四个高性价比工具top pstack strace perf
top命令
top命令可以简单直观地看到CPU 内存等几个关键的性能指标。
按M按照从大到小对内存占用(RES/MEM)排序
按P按照从大到小队CPU占用排序
可以使用组合键xb使用<和>选择需要进行排序的列,这样更灵活,不用单独记如何排序内存和CPU.

pstack命令
pstack命令可以打印进程的调用栈信息,有点像进程的某一时刻的快照,如果反复执行pstack显示的堆栈相同,说明这里可能存在性能问题。

strace命令
strace命令可以显示进程当前正在执行的系统调用,把pstack和strace命令结合起来就能知道进程在用户空间和内核空间大致做了哪些事情。进而可以分析存在性能瓶颈的地方。
不过,有的时候,你也可能会“一无所获”,毕竟这两个工具获得的信息只是“表象”,数据的“含金量”太低,做不出什么有效的决策,还是得靠“猜”。要拿到更有说服力的“数字”,就得 perf 出场了。
perf命令
我常用的 perf 命令是“perf top -K -p xxx”,按 CPU 使用率排序,只看用户空间的调用,这样很容易就能找出最耗费 CPU 的函数。比如,下面这张图显示的是大部分 CPU 时间都消耗在了 ZMQ 库上,其中,内存拷贝调用居然达到了近 30%,是不折不扣的“大户”。所以,只要能把这些拷贝操作减少一点,就能提升不少性能。
如果知道问题的原因出在哪个程序,可以使用如下命令:
perf top -e cpu-clock -p pid

源码级工具
top、pstack、strace 和 perf 属于“非侵入”式的分析工具,不需要修改源码,就可以在软件的外部观察、收集数据。它们虽然方便易用,但毕竟是“隔岸观火”,还是不能非常细致地分析软件,效果不是太理想。
在这里,我要推荐一个专业的源码级性能分析工具:Google Performance Tools,一般简称为 gperftools。它是一个 C++ 工具集,里面包含了几个专门的性能分析工具(还有一个高效的内存分配器 tcmalloc),分析效果直观、友好、易理解,被广泛地应用于很多系统,经过了充分的实际验证。
它的用法也比较简单,只需要在源码里添加三个函数:
ProfilerStart(),开始性能分析,把数据存入指定的文件里;
ProfilerRegisterThread(),允许对线程做性能分析;
ProfilerStop(),停止性能分析。
所以,你只要把想做性能分析的代码“夹”在这三个函数之间就行,运行起来后,gperftools 就会自动产生分析数据。
gperftools工具安装方法:
./autogen.sh
./configure
make -j8
sudo make install
ldconfig 序列化
序列化主要有json protobuf msgpack,详细介绍参考15.序列化:简单通用的数据交换格式有哪些?
TCP
三次握手 四次挥手
进程和线程区别
猴子分桃问题
猴子分桃
有五只猴子,分一堆桃子,可是怎么也平分不了,于是大家同意先去睡觉,明天再说。夜里,一只猴子偷偷起来,把一个桃子扔到山下后正好可以分成五份,它把自己的一份收藏起来就睡觉去了。第二只猴子起来也扔了一个刚好分成五份,也把自己那一份收藏起来。第三、第四、第五只猴子都是这样,扔了一个也刚好可以分成五份。问一共有多少桃子?
这个问题其实大有来头,搜了下是李政道当年去中科大少年班出的一道题,想不出来解法各位也不要妄自菲薄。
分析清楚后使用程序就非常好解决这个问题:
#include <iostream>
#include <cmath>
int main()
{
int n = 5;
int sum = pow(5,5);
int left = pow(4,5) - 4;
std::cout << sum << " "<< left <<std::endl;
return 0;
}运行结果:
[root workspace]#./a.out
3125 1020C++中函数重载、隐藏、覆盖和重写的区别
个税计算
实现代码(有问题欢迎评论指出)
#include <stdio.h>
#define FREE_TAX 800
int taxlevel[] = {0,500,2000,5000,20000,400000,60000,80000,100000,100000};
int taxrate[] = {5,10,15,20,25,30,35,40,45};
#define max(a,b) (((a) > (b))? (a):(b))
double cal_tax(double salary)
{
if(salary <= FREE_TAX)
return 0;
double K = salary - FREE_TAX,sum = 0;
for(int i = 1;i <= 9;i++)
{
if(K > taxlevel[i])
sum += (taxlevel[i] - taxlevel[i-1]) * taxrate[i-1]/100;
else
sum += max(K - taxlevel[i-1],0) * taxrate[i-1]/100;
}
return sum;
}
int main()
{
double salary = 4100;
printf("%f\n",cal_tax(salary));
return 0;
}运行结果:
[root overload]#./a.out
370.000000程序输出
#include <stdio.h>
int main()
{
int arr[] = {1,2,3,4,5};
int *p = (int *)(&arr + 1);
printf("%d\n",*(p-1));
printf("%d",arr[0] += 0x100);
return 0;
}
运行结果:
5
257
C++面试题目总结
C/C++程序的存储空间布局
由上面图看到,栈由高地址向低地址扩展,堆和栈之间没有明显界限。C++存储空间布局和C基本一致,主要包括5个区:堆 栈 全局/静态存储区 常量存储区 代码区。在C语言中未初始化放在.bss段,初始化放在.data段,C++中不再区分这一限制。
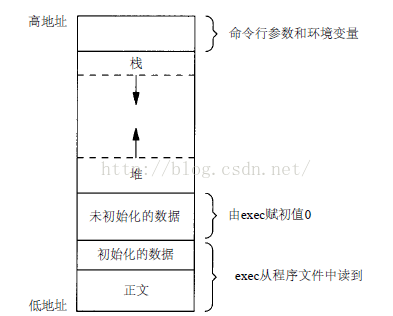
共享库
共享库使得可执行文件中不再需要包含公用的库函数,而只需在所有进程都可引用的存储区中保存这种库历程的一个副本。程序第一次执行或第一次调用某个库函数时,用动态链接方法与共享库函数相链接。这减少了每个可执行文件的长度,但增加了一些运行时间开销。
如何限制类的对象只能在堆上创建
说明:C++ 中的类的对象的建立分为两种:静态建立、动态建立。
静态建立:由编译器为对象在栈空间上分配内存,直接调用类的构造函数创建对象。例如:A a;
动态建立:使用 new 关键字在堆空间上创建对象,底层首先调用 operator new() 函数,在堆空间上寻找合适的内存并分配;然后,调用类的构造函数创建对象。例如:A *p = new A();
限制对象只能建立在堆上:
最直观的思想:避免直接调用类的构造函数,因为对象静态建立时,会调用类的构造函数创建对象。但是直接将类的构造函数设为私有并不可行,因为当构造函数设置为私有后,不能在类的外部调用构造函数来构造对象,只能用 new 来建立对象。但是由于 new 创建对象时,底层也会调用类的构造函数,将构造函数设置为私有后,那就无法在类的外部使用 new 创建对象了。因此,这种方法不可行。
解决方法 1:
将析构函数设置为私有。原因:静态对象建立在栈上,是由编译器分配和释放内存空间,编译器为对象分配内存空间时,会对类的非静态函数进行检查,即编译器会检查析构函数的访问性。当析构函数设为私有时,编译器创建的对象就无法通过访问析构函数来释放对象的内存空间,因此,编译器不会在栈上为对象分配内存。
#include <iostream>
using namespace std;
class A
{
public:
A() {}
void destory()
{
delete this;
}
private:
~A()
{
}
};
int main()
{
A *p = new A();
return 0;
}
该方法存在的问题:
用 new 创建的对象,通常会使用 delete 释放该对象的内存空间,但此时类的外部无法调用析构函数,因此类内必须定义一个 destory() 函数,用来释放 new 创建的对象。
无法解决继承问题,因为如果这个类作为基类,析构函数要设置成 virtual,然后在派生类中重写该函数,来实现多态。但此时,析构函数是私有的,派生类中无法访问。
解决方法 2:
构造函数设置为 protected,并提供一个 public 的静态函数来完成构造,而不是在类的外部使用 new 构造;将析构函数设置为 protected。原因:类似于单例模式,也保证了在派生类中能够访问析构函数。通过调用 create() 函数在堆上创建对象。
#include <iostream>
class A
{
protected:
A() {}
~A() {}
public:
static A* create()
{
return new A();
}
void destory()
{
delete this;
}
};
int main()
{
A *p = A::create();
p->destory();;
return 0;
}限制对象只能建立在栈上
解决方法:将 operator new() 设置为私有。原因:当对象建立在堆上时,是采用 new 的方式进行建立,其底层会调用 operator new() 函数,因此只要对该函数加以限制,就能够防止对象建立在堆上。
#include <iostream>
class A
{
private:
void *operator new(size_t t) {}
void operator delete(void *ptr) {}
public:
A() {}
~A() {}
};
int main()
{
//A *p = new A();//error
A a;
return 0;
}抽象类
接口描述了类的行为和功能,而不需要完成类的特定实现。
C++ 接口是使用抽象类来实现的,抽象类与数据抽象互不混淆,数据抽象是一个把实现细节与相关的数据分离开的概念。
如果类中至少有一个函数被声明为纯虚函数,则这个类就是抽象类。纯虚函数是通过在声明中使用 "= 0" 来指定的,如下所示:
class Box
{
public:
// 纯虚函数
virtual double getVolume() = 0;
private:
double length; // 长度
double breadth; // 宽度
double height; // 高度
};
设计抽象类(通常称为 ABC)的目的,是为了给其他类提供一个可以继承的适当的基类。抽象类不能被用于实例化对象,它只能作为接口使用。如果试图实例化一个抽象类的对象,会导致编译错误。
因此,如果一个 ABC 的子类需要被实例化,则必须实现每个虚函数,这也意味着 C++ 支持使用 ABC 声明接口。如果没有在派生类中重写纯虚函数,就尝试实例化该类的对象,会导致编译错误。
可用于实例化对象的类被称为具体类。
抽象类的实例
请看下面的实例,基类 Shape 提供了一个接口 getArea(),在两个派生类 Rectangle 和 Triangle 中分别实现了 getArea():
#include <iostream>
using namespace std;
// 基类
class Shape
{
public:
// 提供接口框架的纯虚函数
virtual int getArea() = 0;
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// 派生类
class Rectangle: public Shape
{
public:
int getArea()
{
return (width * height);
}
};
class Triangle: public Shape
{
public:
int getArea()
{
return (width * height)/2;
}
};
int main(void)
{
Rectangle Rect;
Triangle Tri;
Rect.setWidth(5);
Rect.setHeight(7);
// 输出对象的面积
cout << "Total Rectangle area: " << Rect.getArea() << endl;
Tri.setWidth(5);
Tri.setHeight(7);
// 输出对象的面积
cout << "Total Triangle area: " << Tri.getArea() << endl;
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Total Rectangle area: 35
Total Triangle area: 17
从上面的实例中,我们可以看到一个抽象类是如何定义一个接口 getArea(),两个派生类是如何通过不同的计算面积的算法来实现这个相同的函数。
设计策略
面向对象的系统可能会使用一个抽象基类为所有的外部应用程序提供一个适当的、通用的、标准化的接口。然后,派生类通过继承抽象基类,就把所有类似的操作都继承下来。
外部应用程序提供的功能(即公有函数)在抽象基类中是以纯虚函数的形式存在的。这些纯虚函数在相应的派生类中被实现。
这个架构也使得新的应用程序可以很容易地被添加到系统中,即使是在系统被定义之后依然可以如此。
右值引用
重载 重写 隐藏的区别
概念解释:
重载:是指同一可访问区内被声明几个具有不同参数列(参数的类型、个数、顺序)的同名函数,根据参数列表确定调用哪个函数,重载不关心函数返回类型。
class A
{
public:
void fun(int tmp);
void fun(float tmp); // 重载 参数类型不同(相对于上一个函数)
void fun(int tmp, float tmp1); // 重载 参数个数不同(相对于上一个函数)
void fun(float tmp, int tmp1); // 重载 参数顺序不同(相对于上一个函数)
int fun(int tmp); // error: 'int A::fun(int)' cannot be overloaded 错误:注意重载不关心函数返回类型
};隐藏:是指派生类的函数屏蔽了与其同名的基类函数,主要只要同名函数,不管参数列表是否相同,基类函数都会被隐藏。
#include <iostream>
using namespace std;
class Base
{
public:
void fun(int tmp, float tmp1) { cout << "Base::fun(int tmp, float tmp1)" << endl; }
};
class Derive : public Base
{
public:
void fun(int tmp) { cout << "Derive::fun(int tmp)" << endl; } // 隐藏基类中的同名函数
};
int main()
{
Derive ex;
ex.fun(1); // Derive::fun(int tmp)
ex.fun(1, 0.01); // error: candidate expects 1 argument, 2 provided
return 0;
}说明:上述代码中 ex.fun(1, 0.01); 出现错误,说明派生类中将基类的同名函数隐藏了。若是想调用基类中的同名函数,可以加上类型名指明 ex.Base::fun(1, 0.01);,这样就可以调用基类中的同名函数。
重写(覆盖):是指派生类中存在重新定义的函数。函数名、参数列表、返回值类型都必须同基类中被重写的函数一致,只有函数体不同。派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有 virtual 修饰。
#include <iostream>
using namespace std;
class Base
{
public:
virtual void fun(int tmp) { cout << "Base::fun(int tmp) : " << tmp << endl; }
};
class Derived : public Base
{
public:
virtual void fun(int tmp) { cout << "Derived::fun(int tmp) : " << tmp << endl; } // 重写基类中的 fun 函数
};
int main()
{
Base *p = new Derived();
p->fun(3); // Derived::fun(int) : 3
return 0;
}
重写和重载的区别:
范围区别:对于类中函数的重载或者重写而言,重载发生在同一个类的内部,重写发生在不同的类之间(子类和父类之间)。
参数区别:重载的函数需要与原函数有相同的函数名、不同的参数列表,不关注函数的返回值类型;重写的函数的函数名、参数列表和返回值类型都需要和原函数相同,父类中被重写的函数需要有 virtual 修饰。
virtual 关键字:重写的函数基类中必须有 virtual关键字的修饰,重载的函数可以有 virtual 关键字的修饰也可以没有。
隐藏和重写,重载的区别:
范围区别:隐藏与重载范围不同,隐藏发生在不同类中。
参数区别:隐藏函数和被隐藏函数参数列表可以相同,也可以不同,但函数名一定相同;当参数不同时,无论基类中的函数是否被 virtual 修饰,基类函数都是被隐藏,而不是重写。
redis sds二进制安全
为什么redis要实现自己的字符串结构呢?主要是C语言中的char 不是二进制安全。同时字符串追加操作需要重新申请内存,然后再拷贝。
Redis 的字符串表示为 sds ,而不是 C 字符串(以 \0 结尾的 char)。
对比 C 字符串, sds 有以下特性:
可以高效地执行长度计算(strlen);
可以高效地执行追加操作(append);
二进制安全;
sds 会为追加操作进行优化:加快追加操作的速度,并降低内存分配的次数,代价是多占用了一些内存,而且这些内存不会被主动释放。
define与typedef的区别
原理:define 作为预处理指令,在编译预处理时进行替换操作,不作正确性检查,只有在编译已被展开的源程序时才会发现可能的错误并报错。typedef 是关键字,在编译时处理,有类型检查功能,用来给一个已经存在的类型一个别名,但不能在一个函数定义里面使用 typedef 。
功能:typedef 用来定义类型的别名,方便使用。define 不仅可以为类型取别名,还可以定义常量、变量、编译开关等。
作用域:define 没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用,而 typedef 有自己的作用域。
指针的操作:typedef 和 define 在处理指针时不完全一样
#include <iostream>
#define INTPTR1 int *
typedef int * INTPTR2;
using namespace std;
int main()
{
INTPTR1 p1, p2; // p1: int *; p2: int
INTPTR2 p3, p4; // p3: int *; p4: int *
int var = 1;
const INTPTR1 p5 = &var; // 相当于 const int * p5; 常量指针,即不可以通过 p5 去修改 p5 指向的内容,但是 p5 可以指向其他内容。
const INTPTR2 p6 = &var; // 相当于 int * const p6; 指针常量,不可使 p6 再指向其他内容。
int a = 10;
p6 = &a;
return 0;
}运行报错信息如下:
[root leetcode]#g++ typedef.cc
typedef.cc: In function ‘int main()’:
typedef.cc:16:11: error: assignment of read-only variable ‘p6’
p6 = &a;
^strcpy函数存在哪些缺陷
strcpy 函数的缺陷:strcpy 函数不检查目的缓冲区的大小边界,而是将源字符串逐一的全部赋值给目的字符串地址起始的一块连续的内存空间,同时加上字符串终止符,会导致其他变量被覆盖。
示例代码:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int var = 0x12345678;
char arr[10];
cout << "Address : var " << &var << endl;
cout << "Address : arr " << &arr << endl;
strcpy(arr, "hello world!");
cout << "var:" << hex << var << endl; // 将变量 var 以 16 进制输出
cout << "arr:" << arr << endl;
return 0;
}
/*
Address : var 0x23fe4c
Address : arr 0x23fe42
var:12002164
arr:hello world!
*/
从上述代码中可以看出,变量 var 的后六位被字符串 "hello world!" 的 "d!\0" 这三个字符改变,这三个字符对应的 ascii 码的十六进制为:\0(0x00),!(0x21),d(0x64)。
原因:变量 arr 只分配的 10 个内存空间,通过上述程序中的地址可以看出 arr 和 var 在内存中是连续存放的,但是在调用 strcpy 函数进行拷贝时,源字符串 "hello world!" 所占的内存空间为 13,因此在拷贝的过程中会占用 var 的内存空间,导致 var的后六位被覆盖。
大端小端字节序
例如假设上述变量x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。大端法从首位开始将是:0x100: 0x01, 0x101: 0x23,..。而小端法将是:0x100: 0x67, 0x101: 0x45,..。字节序详细内容
这个例子在小端模式机器中运行可以看到arr在低地址,var在高地址,arr[9]之后就是var的内存空间了,而在小端模式下,内存地址从低到高为78 56 34 11,因此strcpy拷贝越界后会从低地址到高地址覆盖.
虚函数
#include <iostream>
using namespace std;
class A
{
public:
virtual void v_fun() // 虚函数
{
cout << "A::v_fun()" << endl;
}
};
class B : public A
{
public:
void v_fun()
{
cout << "B::v_fun()" << endl;
}
};
int main()
{
A *p = new B();
p->v_fun(); // B::v_fun()
return 0;
}
纯虚函数:
纯虚函数在类中声明时,加上 =0;
含有纯虚函数的类称为抽象类(只要含有纯虚函数这个类就是抽象类),类中只有接口,没有具体的实现方法;
继承纯虚函数的派生类,如果没有完全实现基类纯虚函数,依然是抽象类,不能实例化对象。编译报错:cannot declare variable ‘c’ to be of abstract type ‘C’
说明:
抽象类对象不能作为函数的参数,不能创建对象,不能作为函数返回类型;
可以声明抽象类指针,可以声明抽象类的引用;
子类必须继承父类的纯虚函数,并全部实现后,才能创建子类的对象。
(高频面试题)虚函数的实现机制
虚函数是依赖于虚函数指针实现,每个拥有虚函数的类都有一个虚函数表,类的对象存在一个虚函数指针,指向实际类型的虚表。虚函数运行的时候,会根据虚函数指针找到正确的虚函数表,从而执行正确的虚函数。
为什么拷贝构造函数必须为引用
原因是:避免拷贝构造函数无限的递归,最终导致栈溢出。
#include <iostream>
using namespace std;
class A
{
private:
int val;
public:
A(int tmp) : val(tmp) // 带参数构造函数
{
cout << "A(int tmp)" << endl;
}
A(const A &tmp) // 拷贝构造函数
{
cout << "A(const A &tmp)" << endl;
val = tmp.val;
}
A &operator=(const A &tmp) // 赋值函数(赋值运算符重载)
{
cout << "A &operator=(const A &tmp)" << endl;
val = tmp.val;
return *this;
}
void fun(A tmp)
{
}
};
int main()
{
A ex1(1);
A ex2(2);
A ex3 = ex1;
ex2 = ex1;
ex2.fun(ex1);
return 0;
}
/*
运行结果:
A(int tmp)
A(int tmp)
A(const A &tmp)
A &operator=(const A &tmp)
A(const A &tmp)
*/
A ex3 = ex1,由于ex3没有实例化,因此调用的是拷贝构造函数。
ex2 = ex1,由于ex2已实例化,因此调用的时拷贝赋值函数。
如果拷贝构造函数A(const A &tmp)中去掉引用,会导致无限递归调用拷贝构造函数,原因是如果没有引用的话将实参赋值给tmp时会调用拷贝构造函数,再次调用拷贝构造树依然会调用拷贝构造函数,因此无限递归导致崩溃。如果去掉&的话会编译失败,实际场景下不会走到崩溃的地步。
[root leetcode]#g++ constcopy.cc
constcopy.cc:15:18: error: invalid constructor; you probably meant ‘A (const A&)’
A(const A tmp) // 拷贝构造函数C++类对象的初始化顺序
构造函数调用顺序:
按照派生类继承基类的顺序,即派生列表中声明的顺序,依次调用基类的构造函数;
按照派生类中成员变量的声名顺序,依次调用派生类中成员变量所属类的构造函数;
执行派生类自身的构造函数。
综上可以得出,类对象的初始化顺序:基类构造函数–>派生类成员变量的构造函数–>自身构造函数
注:
基类构造函数的调用顺序与派生类的派生列表中的顺序有关;
成员变量的初始化顺序与声明顺序有关;
析构顺序和构造顺序相反。
#include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A()" << endl; }
~A() { cout << "~A()" << endl; }
};
class B
{
public:
B() { cout << "B()" << endl; }
~B() { cout << "~B()" << endl; }
};
class Test : public A, public B // 派生列表
{
public:
Test() { cout << "Test()" << endl; }
~Test() { cout << "~Test()" << endl; }
private:
B ex1;
A ex2;
};
int main()
{
Test ex;
return 0;
}
/*
运行结果:
A()
B()
B()
A()
Test()
~Test()
~A()
~B()
~B()
~A()
*/成员函数初始化列表
为什么用成员函数初始化列表会快一些?
数据类型可分为内置类型和用户自定义类型(类类型),对于用户自定义类型,利用成员初始化列表效率高。
原因:用户自定义类型如果使用类初始化列表,直接调用该成员变量对应的构造函数即完成初始化;如果在构造函数中初始化,因为 C++ 规定,对象的成员变量的初始化动作发生在进入构造函数本体之前,那么在执行构造函数的函数体之前首先调用默认的构造函数为成员变量设初值,在进入函数体之后,调用该成员变量对应的构造函数。因此,使用列表初始化会减少调用默认的构造函数的过程,效率高。
#include <iostream>
using namespace std;
class A
{
private:
int val;
public:
A()
{
cout << "A()" << endl;
}
A(int tmp)
{
val = tmp;
cout << "A(int " << val << ")" << endl;
}
};
class Test1
{
private:
A ex;
public:
Test1() : ex(1) // 成员列表初始化方式
{
}
};
class Test2
{
private:
A ex;
public:
Test2() // 函数体中赋值的方式
{
ex = A(2);
}
};
int main()
{
Test1 ex1;
cout << endl;
Test2 ex2;
return 0;
}
/*
运行结果:
A(int 1)
A()
A(int 2)
*/运行结果:
A(int 1)
A()
A(int 2)可以看到在Test2类中,在进构造函数之前调用了类A的默认构造函数,因此针对自定义构造函数使用初始化列表能够减少默认构造函数调用提升性能。
构造函数可以是虚函数吗?
1.构造对象的时候,必须知道对象的实际类型。而虚函数行为是在运行期间确定实际类型的,在构造对象的时,对象还没有构造成功,编译器无法知道对象的实际类型是该类本身还是其派生类。
2.虚函数的运行依赖于虚函数指针,而虚函数指针在构造函数中进程初始化,让它指向正确的虚函数表,而在对象构造期间,虚函数指针还未构造完成。
C++多态实现
多态分为两种,一种是运行时的多态,一种是编译时的多态。前者称为动态绑定,后者称为静态绑定。动态绑定时由虚函数来实现,静态绑定是由函数重载来实现。
线程安全和可重入函数
线程安全:
一个函数被称为线程安全的(thread-safe),当且仅当被多个并发进程反复调用时,它会一直产生正确的结果。
可重入:
如果一个函数被不同的执行流程调用,就有可能在上一次调用还没有完成时再次进入该函数,这就叫重入。比如当前进程正在执行malloc,收到信号,在信号处理函数中同样调用malloc函数,会导致死锁,因为mallo函数不可重入。实际工作中遇到过这种问题,在信号处理函数中调用malloc,非必现程序死锁。
线程安全和可重入关系
可重入比线程安全更加严格,线程安全的函数不一定可重入,但可重入函数一定是线程安全的。
TCP UDP区别
UDP TCP
是否连接 无连接 面向连接
是否可靠 不可靠传输,不使用流量控制和拥塞控制 可靠传输,使用流量控制和拥塞控制
连接对象个数 支持一对一,一对多,多对一和多对多交互通信 只能是一对一通信
传输方式 面向报文 面向字节流
首部开销 首部开销小,仅8字节 首部最小20字节,最大60字节
适用场景 适用于实时应用(IP电话、视频会议、直播等) 适用于要求可靠传输的应用,例如文件传输
TCP向上层提供面向连接的可靠服务,UDP向上层提供无连接的不可靠服务,虽然UDP并没有TCP传输来的准确,但是也能在很多实时性要求高的地方有所作为,对数据准确性要求高,速度可以相对较慢的可以选用TCP。
智力题
智力题,100本书,两个人轮流拿,每次拿1~5本,你先拿,有没有啥策略可以保证你可以拿到最后一本?
答案:
先拿4本,然后对方拿N本,自己每次都拿6-N本,如果按照策略 4 + 6 * 15 = 94,这样对方无论如何拿基本,自己都将拿到最后一本。
多个动态库链接顺序
需要注意的时,在链接命令中给出所依赖的库时,需要注意库之间的依赖顺序,依赖其他库的库一定要放在被依赖库的前面,这样才能真正避免undefined reference的错误。
linux互斥锁 递归锁 非递归锁
互斥锁可以分为递归锁(recursive mutex)和非递归锁(non-recursive mutex)。可递归锁也可称为可重入锁(reentrant mutex),非递归锁又叫不可重入锁(non-reentrant mutex)。
二者唯一的区别是,同一个线程可以多次获取同一个递归锁,不会产生死锁。而如果一个线程多次获取同一个非递归锁,则会产生死锁。
在大部分介绍如何使用互斥锁的文章和书中,这两个概念很少提及,造成很多人根本不知道这个概念。
list与vector
list的空间是按需分配,内存空间不一定连续,在插入新元素时不会引起迭代器失效,删除元素时只有当前元素的迭代器失效,插入删除元素常数时间。
vector的空间是线性连续的,在空间不足的情况下插入元素时需要三个步骤
(1)开辟新的大块内存区域
(2)从旧空间拷贝数据到新空间
(3)释放旧空间(注:在插入新元素时,原空间后的内存大小不足以满足新内存大小的需求时,才会新找空间),此操作较复杂,因此vector内部分配空间时总是供大于需,即按2*size大小来分配空间,避免频繁移动数据操作,因此,插入删除操作可能会引起迭代器失效。
扩展有关vector的两个概念:
容量:总的内存空间(由迭代器start和end_of_storage标识)
大小:已用空间(由迭代器start和finish标识)
vector resize()实现
void resize(size_type new_size, const T& x)
{
if (new_size < size())
erase(begin() + new_size, end());
else
insert(end(), new_size - size(), x);
}
void resize(size_type new_size)
{
resize(new_size, T());
}TIME_WAIT作用
TIME_WAIT状态存在有两个原因。
1)、可靠终止TCP连接。如果最后一个ACK报文因为网络原因被丢弃,此时server因为没有收到ACK而超时重传FIN报文,处于TIME_WAIT状态的client可以继续对FIN报文做回复,向server发送ACK报文。
2)、保证让迟来的TCP报文段有足够的时间被识别和丢弃。连接结束了,网络中的延迟报文也应该被丢弃掉,以免影响立刻建立的新连接。
问题:客户端在发送第一个FIN之后,服务器为什么不将ACK和FIN一起发送回客户端(就像三次握手那样),而是将ACK和FIN分别发送呢?
答案:服务器收到FIN后,要回复客户端“我收到了”,要不然客户端以为服务端没收到,就会重发,但是服务端自己本身可能还有数据没发送完成,等自身的数据发送完成后,再向客户端发送close请求。
{kind=link}
字符串排序
一、字符串排序:
输入:字符串由数字、小写字母、大写字母组成。输出:排序好的字符串。
排序的标准:
(1). 数字>小写字母>大写字母。
(2). 数字、字母内部的相对顺序不变。
(3). 额外存储空间:O(1)。
思路分析:
面试的时候最开始想使用双指针法,模拟了下比较过程,发现存在问题。
然后想了一种思路,将字符与数组映射int arr[256] = {//字符0 - 9对应下标值为0,//字符a - z对应下标值为1,//字符A-Z对应下标值为2},这样的话构造这个数组映射关系比较麻烦,最终想了一种写法:
#include <iostream>
#include <string>
using namespace std;
int get_value_type(char c)
{
if(c >= '0' && c <= '9')
return 0;
else if(c >= 'a' && c <= 'z')
return 1;
else if(c >= 'A' && c <= 'Z')
return 2;
else
return -1;
}
std::string stringSort(std::string & str)
{
//面试的时候写的冒泡排序,快速排序性能更佳
for(int i = str.size() - 1;i >= 0;i--)
{
for(int j = 0;j < i;j++)
{
if(get_value_type(str[j]) > get_value_type(str[j+1]))
swap(str[j],str[j+1]);
}
}
return str;
}
int main()
{
string res = "abcd4312ABDC";
string result = stringSort(res);
cout << result << endl;
return 0;
}走迷宫问题
二、走迷宫
定义一个二维数组:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的最短路线。
对于上述示例,则输出:
(0, 0) (1, 0) (2, 0) (2, 1) (2, 2) (2, 3) (2, 4) (3, 4) (4, 4)
完成如下函数,输出最短路线:
void PuzzleMaze(const int** maze,int m, int n) {
// m为迷宫的高,n为迷宫的宽
}智力题
猴子分苹果问题,根据以下信息计算总共有多少个苹果?
1.每个猴子分3个,则剩余30个
2.每个猴子分10个,只有一个猴子不够分
答:假设有x个猴子,苹果的总个数:3x + 30
根据第二个条件 3x + 30 < 10x && 3x+30 >= (x-1) * 10,解这两个不等式 x > 30/7 x<=40/7,因此 x = 5,苹果个数3*5+30 = 45
编程题-数组交集
求两升序数组,cout输出交集,要求只能用一个函数,时间复杂度为O(n)。
void find(int a[],int m,int b[],int k)
{
}
leetcode上有两道数组交集问题349和350.
这道题其实有很多变种,比如349题,交集中不包含重复数字,AC代码:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> hash(nums1.begin(),nums1.end());
unordered_set<int> res;
for(auto num:nums2)
{
if(hash.count(num))
res.insert(num);
}
vector<int> ans(res.begin(),res.end());
return ans;
}
};双指针版本:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//排序
sort(nums1.begin(),nums1.end());
sort(nums2.begin(),nums2.end());
int m = nums1.size() , n = nums2.size();
int i = 0,j = 0;
vector<int> res;
while(i < m && j < n)
{
if(nums1[i] == nums2[j])
{
res.push_back(nums1[i]);
i++;
j++;
}else if(nums1[i] > nums2[j])
{
j++;
}else{
i++;
}
//过滤重复元素
while(0 < i && i < m && nums1[i] == nums1[i-1]) i++;
while(0 < j && j < n && nums2[j] == nums2[j-1]) j++;
}
return res;
}
};而350题则是按照实际出现的次数输出。AC 代码:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
unordered_map<int,int> hash;
vector<int> res;
for(auto num:nums1)
hash[num] += 1;
for(auto num:nums2)
{
if(hash[num] > 0)
{
res.push_back(num);
hash[num] -= 1;
}
}
return res;
}
};对应双指针版本:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
//排序
sort(nums1.begin(),nums1.end());
sort(nums2.begin(),nums2.end());
int m = nums1.size() , n = nums2.size();
int i = 0,j = 0;
vector<int> res;
while(i < m && j < n)
{
if(nums1[i] == nums2[j])
{
res.push_back(nums1[i]);
i++;
j++;
}else if(nums1[i] > nums2[j])
j++;
else
i++;
}
return res;
}
};C++ nullptr作用
nullptr 出现的目的是为了替代 NULL。在某种意义上来说,传统 C++ 会把 NULL、0 视为同一种东西,这取决于编译器如何定义 NULL,有些编译器会将 NULL 定义为 ((void*)0),有些则会直接将其定义为 0。
C++ 不允许直接将 void * 隐式转换到其他类型。但如果编译器尝试把 NULL 定义为 ((void*)0),那么在下面这句代码中:
char *ch = NULL;没有了 void * 隐式转换的 C++ 只好将 NULL 定义为 0。而这依然会产生新的问题,将 NULL 定义成 0 将导致 C++ 中重载特性发生混乱。考虑下面这两个 foo 函数:
void foo(char*);
void foo(int);
那么 foo(NULL); 这个语句将会去调用 foo(int),从而导致代码违反直觉。
为了解决这个问题,C++11 引入了 nullptr 关键字,专门用来区分空指针、0。而 nullptr 的类型为 nullptr_t,能够隐式的转换为任何指针或成员指针的类型,也能和他们进行相等或者不等的比较。
使用Kafka的好处和坏处
优势:
1.架构解耦
2.流量控制
3.异步处理
缺点:
1.消息丢失
2.消息重复
3.消息乱序
4.消息堆积
kafka如何解决这些问题
一.消息丢失。
日志场景,偶尔某条消息丢失也没关系。要求消息一定不丢失,从三个方面设置:
a.生产者端,必须等消息的成功确认。kafka端有ack=all选项。
b.broker端,消息落盘再回复成功。而且replica数一定要大于1,保证每个分区有多个副本.
c.消费者端,必须要等消息处理完毕再提交。
二.消息重复
消息重复的问题是由于生产者端可能由于某种原因没有收到broker端的成功确认,然后重复发送消息导致的。
如果生产者端不要求消息不丢失,那么只发送不管发送结果,就不会产生消息重复问题。
要保证消息不丢失,broker端必定会产生消息重复问题。
要避免这个问题,只能从消费者端解决。简而言之,就是保证消费端消费的幂等性。
保证消费端的消费幂等性,有如下几个方法:
1.每个消息给一个全局id,消费端消费后将id写到redis。每次消费时需要先去redis查一遍全局消息id
2.mysql插入数据,先查一下主键。有就update。
3.数据库设置唯一键。
三.消息乱序
kafka多分区之间数据可能是不是有序的。只有单个分区内的数据可以保证唯一性。
要保证唯一数据有序,唯一的办法只能是单topic单分区。生产端发送数据的时候指定key,这样数据就会被发送到同一个分区。
消费者端分两个步骤:消费+处理。一般处理比较耗时。我们可以采用一个线程专门消费,然后对clientId进行哈希,将消息分别哈希到N个内存消息队列,每个内存消息队列再用一个线程去处理。4C32G的机器,一般可以达到1000的qps。
四.消息挤压
消息挤压的原因无非是消费能力与生产能力不匹配。
先从业务逻辑上优化,能批量执行的,则先批量执行。优化后还是没法提高,只能水平扩容。
CAP理论
CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
这里需要特别强调一致性策略,主要有三种:
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。
如果能容忍后续的部分或者全部访问不到,则是弱一致性。
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
CAP中说,不可能同时满足的这个一致性指的是强一致性。
智能指针
微软docs上有一篇文章介绍的非常好:
RAII方式实现锁
参考第一篇文章中方法自己实现的代码:
#include <thread>
#include <mutex>
class Mutex
{
public:
Mutex();
~Mutex();
void Lock();
void Unlock();
private:
std::mutex mtx;
//禁用拷贝
Mutex(const Mutex&);
void operator=(const Mutex&);
};mutex.cc
#include "mutex.hpp"
Mutex::Mutex()
{
}
Mutex::~Mutex()
{
}
void Mutex::Lock()
{
mtx.lock();
}
void Mutex::Unlock()
{
mtx.unlock();
}mutexlock.hpp
#include "mutex.hpp"
class MutexLock {
public:
explicit MutexLock(Mutex *mu):m_mu(mu)
{
this->m_mu->Lock();
}
~MutexLock()
{
this->m_mu->Unlock();
}
private:
Mutex *const m_mu;
//禁用拷贝
MutexLock(const MutexLock&);
void operator=(const MutexLock&);
};main.cc
#include <iostream>
#include "mutexlock.hpp"
static Mutex mtx;
static int sum = 0;
#define THREAD_NUM 1000
void print_thread_id (int id) {
MutexLock lock(&mtx);
// critical section (exclusive access to std::cout signaled by locking mtx):
//std::cout << "thread #" << id << '\n';
sum += 1;
}
int main ()
{
std::thread threads[THREAD_NUM];
// spawn 1000 threads:
for (int i=0; i<THREAD_NUM; ++i)
threads[i] = std::thread(print_thread_id,i+1);
for (auto& th : threads) th.join();
std::cout << sum << std::endl;
return 0;
}编译运行
[root raii]#g++ -std=c++14 *.cc -lpthread
[root raii]#
[root raii]#./a.out
1000二分查找
基础的二分查找参考leetcode704
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0,right = nums.size() - 1;
while(left <= right)
{
int mid = (right - left)/2 + left;
if(nums[mid] == target)
return mid;
else if(nums[mid] < target)
left = mid + 1;
else
right = mid - 1;
}
return -1;
}
};size_t 类型
使用动态库和静态库的优劣
根据链接的时期不同,分为动态库和静态库。静态库是在程序编译时链接的,动态库是在程序运行时链接的。
动态库在内存中只保留一份,静态库不同的二进制会保存多份,因此使用静态库编译后二进制较大。静态库具有更好的移植性,不需要处理依赖的库。
静态库的更新比较麻烦,如果发现了bug,需要将所有依赖这个静态库的程序重新编译。动态库的更新比较简单,直接替换即可。
API和ABI的区别
所谓ABI,是指应用程序二进制接口(Application Binary Interface, ABI),ABI,Application Binary Interface
main.c
#include <assert.h>
#include <stdlib.h>
#include "mylib.h"
int main(void) {
mylib_mystruct *myobject = mylib_init(1);
assert(myobject->old_field == 1);
free(myobject);
return EXIT_SUCCESS;
}mylib.c
#include <stdlib.h>
#include "mylib.h"
mylib_mystruct* mylib_init(int old_field) {
mylib_mystruct *myobject;
myobject = malloc(sizeof(mylib_mystruct));
myobject->old_field = old_field;
return myobject;
}mylib.h
#ifndef MYLIB_H
#define MYLIB_H
typedef struct {
int old_field;
} mylib_mystruct;
mylib_mystruct* mylib_init(int old_field);
#endif编译命令:
cc='gcc -pedantic-errors -std=c89 -Wall -Wextra'
$cc -fPIC -c -o mylib.o mylib.c
$cc -L . -shared -o libmylib.so mylib.o
$cc -L . -o main.out main.c -lmylib
LD_LIBRARY_PATH=. ./main.out如果我们修改结构体mylib_mystruct如下:
typedef struct {
int new_field;
int old_field;
} mylib_mystruct;重新编译libmylib.so,但是不编译main.out,运行main.out崩溃:
[root abi]#LD_LIBRARY_PATH=. ./main.out
main.out: main.c:8: main: Assertion `myobject->old_field == 1' failed.这是因为我们在old_field字段前添加了new_field,导致产生了ABI问题,如果我们修改结构体mylib_mystruct如下:
typedef struct {
int old_field;
int new_field;
} mylib_mystruct;那么运行main.out正常。因为old_field还是在结构体第一个位置,没有产生ABI问题。
服务器中存在大量time_wait状态
编程题
微信跳一跳
描述信息
从起点开始接下来有 100 个方块(即:一格一格跳 100 次到终点),相邻方块间的距离都为 1,每个方块上有增加体力的食用蘑菇或减少体力的毒蘑菇,蘑菇带来的体力改变是已知的。一个人初始体力为 m,每次可以往前跳任意个方块,体力耗尽就会死掉。
Q: 每跳一次消耗的体力与跳的距离成正比,比例为 1。问这个人能否跳到终点,如果能,求可能剩余的最大体力。
例:初始体力 5,共 5 个方块,分别为:[0,0,-1,2,0],如果一格一格跳,跳一次掉 1 点体力,则到达终点剩余体力 1,如果直接跳到2(消耗4个体力,吃掉蘑菇获得2个体力,此时剩余3个体力,跳到终点剩余1个体力。
面试时写的代码:
#include <iostream>
using namespace std;
int distance(int* arr,int len,int total)
{
if(!arr || total <= 0) return -1;
int ans = -1;
for(int i = 0;i < len;)
{
int start = i;
//find arr[i] > 0
while(arr[i] < 0) i++;
//判断能不能跳过去
if(total >= i - start)
{
total += arr[i++] - (i - start);
}
else
return -1;
}
return total;
}
int main() {
int arr1[] = {0,1,2,0,-2,3};
int arr2[] = {0,0,-1,2,0};
int total = 5;
int ans = distance(arr1,sizeof(arr1)/sizeof(int),total);
int res = distance(arr2,5,total);
cout << ans << endl;
cout << res << endl;
}面试结束后优化代码如下:
#include <iostream>
#include <vector>
using namespace std;
int distance(const vector<int> &num,int total)
{
int size = num.size();
if(size == 0 || total <= 0) return -1;
int ans = -1;
for(int i = 0;i < size;)
{
//记录开始位置
int start = i;
//找到下一个大于0的元素
while(num[i] <= 0) i++;
//判断体力能否满足跳过去
if(total >= i - start + 1)
{
//消耗体力+吸收能量
total += num[i] - (i - start + 1);
i++;
}
else
return -1;
}
return total;
}
int main() {
vector<int> num = {0,1,2,0,-2,3};
int total = 5;
int res = distance(num,total);
cout << res << endl;
vector<int> vec = {0,-1,-2,-3,-2,3};
res = distance(vec,total);
cout << res << endl;
}C++中的左值和右值
C++11为了支持移动操作,引用了新的引用类型-右值引用。
所谓右值引用就是绑定到右值的引用。
为了区分右值引用,引入左值引用概念,即常规引用。
那左值与右值是是什么?**
1、左值与右值
一。左值 lvalue 是有标识符、可以取地址的表达式
变量、函数或数据成员的名字
返回左值引用的表达式,如 ++x、x = 1、cout << ' '
字符串字面量如 "hello world"
表达式是不是左值,就看是否可以取地址,或者返回类型是否可以用(常规)引用来接收:
int x = 0;
cout << "(x).addr = " << &x << endl;
cout << "(x = 1).addr = " << &(x = 1) << endl; //x赋值1,返回x
cout << "(++x).addr = " << &++x << endl; //x自增1,返回x
cout << "hello world = " << &("hello world") << endl;
cout << "cout << ' ' = " << &(cout << ' ') << endl;运行结果:
(x).addr = 0x22fe4c
(x = 1).addr = 0x22fe4c
(++x).addr = 0x22fe4c
hello world = 0x40403a
cout << ' ' = 0x7fff805e51d0
C++中的字符串字面量,可以称为字符串常量,表示为const char[N],其实是地址常量表达式。
在内存中有明确的地址,不是临时变量。
二。纯右值 prvalue 是没有标识符、不可以取地址的表达式,一般称为“临时对象”
返回非引用类型的表达式,如 x++、x + 1、make_shared(42)
除字符串字面量之外的字面量,如 42、true
//cout << "(x++).addr = " << &x++ << endl; //返回一个值为x的临时变量,再把x自增1
//cout << "(x + 1).addr = " << &(x + 1) << endl; //返回一个值为x+1的临时变量
//cout << "(42).addr = " << &(42) << endl; //返回一个值为42的临时变量
//cout << "(true).addr = " << &(true) << endl; //返回一个值为true的临时变量
编译出错:
每行代码报错:表达式必须为左值或函数指示符
因为以上表达式都返回的是“临时变量”,是不可以取地址的
删除链表倒数第N个结点
删除字符串中指定字符串
线程池设计C++
能否支持热切换(调整线程数)
执行echo "hello" > file 完整执行过程
使用strace跟踪,执行过程:
[root overload]#strace echo "hello" > file
execve("/usr/bin/echo", ["echo", "hello"], 0x7ffdba575cc8 /* 35 vars */) = 0
brk(NULL) = 0x1a0f000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f3e6e481000
…………………………………………………………………………………………
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=92079, ...}) = 0
mmap(NULL, 92079, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f3e6e46a000
close(3) = 0
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0`&\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=2156352, ...}) = 0
mmap(NULL, 3985920, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f3e6de93000
mprotect(0x7f3e6e057000, 2093056, PROT_NONE) = 0
mmap(0x7f3e6e256000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1c3000) = 0x7f3e6e256000
mmap(0x7f3e6e25c000, 16896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f3e6e25c000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f3e6e469000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f3e6e467000
arch_prctl(ARCH_SET_FS, 0x7f3e6e467740) = 0
mprotect(0x7f3e6e256000, 16384, PROT_READ) = 0
mprotect(0x606000, 4096, PROT_READ) = 0
mprotect(0x7f3e6e482000, 4096, PROT_READ) = 0
munmap(0x7f3e6e46a000, 92079) = 0
brk(NULL) = 0x1a0f000
brk(0x1a30000) = 0x1a30000
brk(NULL) = 0x1a30000
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=106172832, ...}) = 0
mmap(NULL, 106172832, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f3e67951000
close(3) = 0
fstat(1, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f3e6e480000
write(1, "hello\n", 6) = 6
close(1) = 0
munmap(0x7f3e6e480000, 4096) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++如何查看系统中处于TIME_WAIT状态的连接数
[root ~]#netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
LISTEN 11
ESTABLISHED 1
[root ~]#stl中unordered_map 和map底层实现差异
内部实现机理
map:
map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
unordered_map:
unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的,但是查找速度比较快,但哈希表的建立比较耗时,特别是当哈希表内冲突较多时会导致查找效率降低。
介绍网络IO的发展历程
腾讯技术工程公众号中有一篇相对比较精炼的文章,面试中常问poll select epoll等相关知识。
emplace_back和push_back
当 push_back、insert、reserve、resize 等函数导致内存重分配时,或当 insert、erase 导致元素位置移动时,vector 会试图把元素“移动”到新的内存区域。vector 通常保证强异常安全性,如果元素类型没有提供一个保证不抛异常的移动构造函数,vector 通常会使用拷贝构造函数。因此,对于拷贝代价较高的自定义元素类型,我们应当定义移动构造函数,并标其为 noexcept,或只在容器中放置对象的智能指针。这就是为什么我之前需要在 smart_ptr 的实现中标上 noexcept 的原因。
#include <iostream>
#include <vector>
using namespace std;
class Obj1 {
public:
Obj1()
{
cout << "Obj1()\n";
}
Obj1(const Obj1&)
{
cout << "Obj1(const Obj1&)\n";
}
Obj1(Obj1&&)
{
cout << "Obj1(Obj1&&)\n";
}
};
class Obj2 {
public:
Obj2()
{
cout << "Obj2()\n";
}
Obj2(const Obj2&)
{
cout << "Obj2(const Obj2&)\n";
}
Obj2(Obj2&&) noexcept
{
cout << "Obj2(Obj2&&)\n";
}
};
int main()
{
vector<Obj1> v1;
v1.reserve(2);
v1.emplace_back();
v1.emplace_back();
v1.emplace_back();
vector<Obj2> v2;
v2.reserve(2);
v2.emplace_back();
v2.emplace_back();
v2.emplace_back();
}运行结果:
Obj1()
Obj1()
Obj1()
Obj1(const Obj1&)
Obj1(const Obj1&)
Obj2()
Obj2()
Obj2()
Obj2(Obj2&&)
Obj2(Obj2&&)C++11 开始提供的 emplace… 系列函数是为了提升容器的性能而设计的。你可以试试把 v1.emplace_back() 改成 v1.push_back(Obj1())。对于 vector 里的内容,结果是一样的;但使用 push_back 会额外生成临时对象,多一次(移动或拷贝)构造和析构。如果是移动的情况,那会有小幅性能损失;如果对象没有实现移动的话,那性能差异就可能比较大了。
介绍下select poll epoll的用法
数组不排序判断是否为等差数列
C++中如何实现信号量
灯泡问题
使用迭代器删除vector中元素(比如下标为偶数)
编程题-动态规划
假设有两颗一模一样的鸡蛋,一栋100层高的楼落下,想知道在那一层落下鸡蛋会摔碎,应该如何用最少的测试次数。
define 与 inline区别
内联函数是在编译时展开,而宏在编译预处理时展开;在编译的时候,内联函数直接被嵌入到目标代码中去,而宏只是一个简单的文本替换。
内联函数是真正的函数,和普通函数调用的方法一样,在调用点处直接展开,避免了函数的参数压栈操作,减少了调用的开销。而宏定义编写较为复杂,常需要增加一些括号来避免歧义。
宏定义只进行文本替换,不会对参数的类型、语句能否正常编译等进行检查。而内联函数是真正的函数,会对参数的类型、函数体内的语句编写是否正确等进行检查。
三次握手
accept是在三次握手哪一次?
backlog作用
优化memcpy库函数